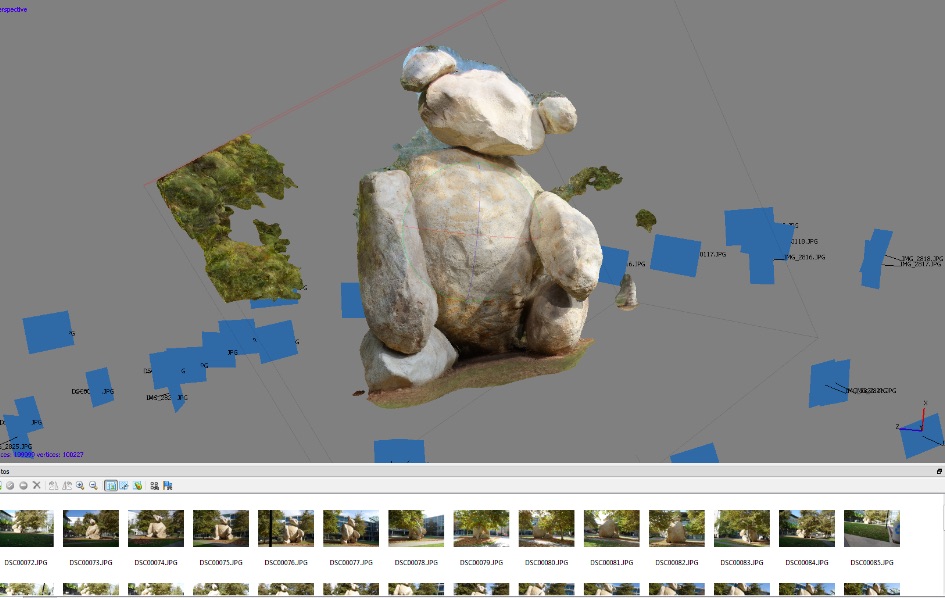
 Structure From Motion: 3D models are useful in various forms of surveying and machine perception. Structure from Motion (SfM) is a technique that uses multiple camera views to estimate the 3D structure of an object or scene. SfM is low-cost and robust to various types of noise, which make it an ideal tool for many fields like robotics, surveying, and archaeology. Yet, lengthy processing times and power requirements of SfM workstations limit its effectiveness in the field. The goal of this project is to decrease both processing time and power constraints through a heterogeneous implementation of SfM algorithms.
Structure From Motion: 3D models are useful in various forms of surveying and machine perception. Structure from Motion (SfM) is a technique that uses multiple camera views to estimate the 3D structure of an object or scene. SfM is low-cost and robust to various types of noise, which make it an ideal tool for many fields like robotics, surveying, and archaeology. Yet, lengthy processing times and power requirements of SfM workstations limit its effectiveness in the field. The goal of this project is to decrease both processing time and power constraints through a heterogeneous implementation of SfM algorithms.
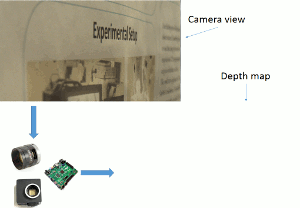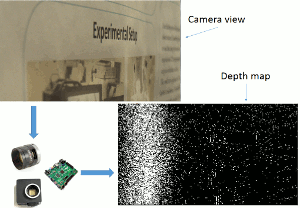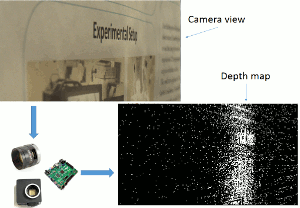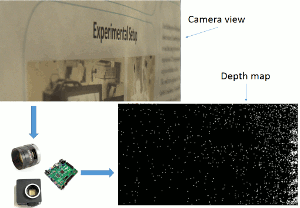 Dynamic Vision Sensor (DVS) cameras are ultra-fast image sensors with the ability to produce 1M events per pixel per second. They can quickly produce a depth image when used in combination with a fast and high-resolution liquid lens by sweeping the lens and detecting high frequencies in the image. The calculation to detect the high frequencies needs to be fast to process every event received from the DVS camera. Currently, for proof of concept and development purposes, we are using a CPU. To meet the speed requirements, this application will be implemented using FPGA.
Dynamic Vision Sensor (DVS) cameras are ultra-fast image sensors with the ability to produce 1M events per pixel per second. They can quickly produce a depth image when used in combination with a fast and high-resolution liquid lens by sweeping the lens and detecting high frequencies in the image. The calculation to detect the high frequencies needs to be fast to process every event received from the DVS camera. Currently, for proof of concept and development purposes, we are using a CPU. To meet the speed requirements, this application will be implemented using FPGA.
 Data Compression: Major cloud computing providers own large number of data centers, each containing hundreds of thousands of servers: Google (1 million), Amazon (0.5 million), Microsoft (200k). A recent study shows that power consumption accounts for over 35% of the total cost of data centers, which costs millions of dollars per year. To reduce the power consumption of data center, researchers experimented running data center applications on an FPGA (e.g., Bing). The aim of this research is to evaluate implementation of data encoding algorithm, a canonical Huffman encoding, a popular data center application using high-level synthesis tools. Specifically, we use Vivado HLS from Xilinx to design and implement high performance low power canonical Huffman encoding [ASAP14, Slides].
Data Compression: Major cloud computing providers own large number of data centers, each containing hundreds of thousands of servers: Google (1 million), Amazon (0.5 million), Microsoft (200k). A recent study shows that power consumption accounts for over 35% of the total cost of data centers, which costs millions of dollars per year. To reduce the power consumption of data center, researchers experimented running data center applications on an FPGA (e.g., Bing). The aim of this research is to evaluate implementation of data encoding algorithm, a canonical Huffman encoding, a popular data center application using high-level synthesis tools. Specifically, we use Vivado HLS from Xilinx to design and implement high performance low power canonical Huffman encoding [ASAP14, Slides].
 Sorting is a widespread and fundamental data processing task especially in the age of big data. While efficient FPGA implementations of sorting algorithms exist, they lack portability and maintainability because they are written in low-level hardware description languages that require substantial domain expertise to develop and maintain. To address this problem, we developed a framework that generates sorting architectures for different requirements (speed, area, power, etc.). For example, insertion sort is selected for lists smaller than 15 elements and then switches to merge sort for larger lists. The result is a system that minimizes knowledge required to design high performance sorting architectures for an FPGA.
Sorting is a widespread and fundamental data processing task especially in the age of big data. While efficient FPGA implementations of sorting algorithms exist, they lack portability and maintainability because they are written in low-level hardware description languages that require substantial domain expertise to develop and maintain. To address this problem, we developed a framework that generates sorting architectures for different requirements (speed, area, power, etc.). For example, insertion sort is selected for lists smaller than 15 elements and then switches to merge sort for larger lists. The result is a system that minimizes knowledge required to design high performance sorting architectures for an FPGA.
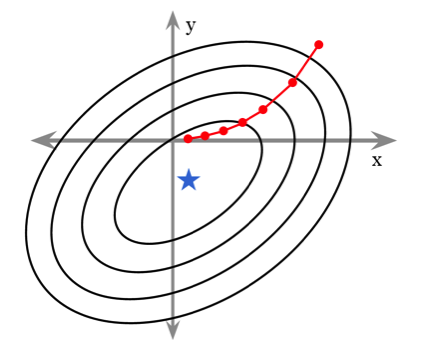 Nonnegative Least Squares (NNLS) optimization is an important algorithmic component of many problems in science and engineering, including image segmentation, spectral deconvolution, and reconstruction of compressively sensed data. Each of these areas can benefit from high performance implementations suitable for embedded applications. Unfortunately, the NNLS problem has no solution expressible in closed-form, and many popular algorithms are not amenable to compact and scalable hardware implementation. In this project we have developed an efficient hardware architecture to accelerate a recently developed and highly parallel algorithm for NNLS. This project also extends the algorithm using truncation of the mantissa bits in fixed point implementations to greatly accelerate convergence.
Nonnegative Least Squares (NNLS) optimization is an important algorithmic component of many problems in science and engineering, including image segmentation, spectral deconvolution, and reconstruction of compressively sensed data. Each of these areas can benefit from high performance implementations suitable for embedded applications. Unfortunately, the NNLS problem has no solution expressible in closed-form, and many popular algorithms are not amenable to compact and scalable hardware implementation. In this project we have developed an efficient hardware architecture to accelerate a recently developed and highly parallel algorithm for NNLS. This project also extends the algorithm using truncation of the mantissa bits in fixed point implementations to greatly accelerate convergence.
 DNA Sequencing: The conventional short-read technology is incapable of aligning large-scale genomes (more than 10K bases) due to the frequent repetitions of the base patterns. A fundamentally different technology solves this problem by aligning optical labels on the DNA molecules instead of the conventional ATCG bases. However, this alignment algorithm is computationally intensive. For example, the run-time of mapping a human genome is on the order of 10,000 hours on a sequential CPU. Therefore, in order to practically apply this new technology in genome research, accelerated approaches are desirable. We accelerated this novel optical labeled de novo genome assembly algorithm on multi-core CPU, GPU, and FPGA. Against the sequential software baseline, our multi-thread CPU design achieved a 8.4X speedup while the GPU and FPGA designs achieved 13.6X and 115X speedups respectively [FPL14].
DNA Sequencing: The conventional short-read technology is incapable of aligning large-scale genomes (more than 10K bases) due to the frequent repetitions of the base patterns. A fundamentally different technology solves this problem by aligning optical labels on the DNA molecules instead of the conventional ATCG bases. However, this alignment algorithm is computationally intensive. For example, the run-time of mapping a human genome is on the order of 10,000 hours on a sequential CPU. Therefore, in order to practically apply this new technology in genome research, accelerated approaches are desirable. We accelerated this novel optical labeled de novo genome assembly algorithm on multi-core CPU, GPU, and FPGA. Against the sequential software baseline, our multi-thread CPU design achieved a 8.4X speedup while the GPU and FPGA designs achieved 13.6X and 115X speedups respectively [FPL14].
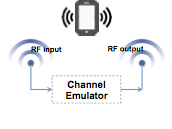 SDR Emulation: Simulating different wireless scenarios requires a virtual platform to test and verify different wireless systems in laboratory. Unlike outdoor field test in real environments, which is demanding in time, energy, as well as human power, emulating channel effects on a digital system allows engineers to save efforts especially when the testing scenario is difficult to repeat, e.g., communications between ships, planes, and satellites. In this project, our mission is to achieve fundamental requirements of wireless digital channel emulator – high throughput performance and scalability – as well as to capture a raw signal in a broad spectrum of frequency hopping condition. We implemented key modules using high level synthesis, e.g., processing digital signals for tracking an input signal frequency to reduce the bandwidth of the data that must be processed [FPT12, FPL14].
SDR Emulation: Simulating different wireless scenarios requires a virtual platform to test and verify different wireless systems in laboratory. Unlike outdoor field test in real environments, which is demanding in time, energy, as well as human power, emulating channel effects on a digital system allows engineers to save efforts especially when the testing scenario is difficult to repeat, e.g., communications between ships, planes, and satellites. In this project, our mission is to achieve fundamental requirements of wireless digital channel emulator – high throughput performance and scalability – as well as to capture a raw signal in a broad spectrum of frequency hopping condition. We implemented key modules using high level synthesis, e.g., processing digital signals for tracking an input signal frequency to reduce the bandwidth of the data that must be processed [FPT12, FPL14].
 3D Scanning: Triangulation-based active 3D scanners, or profile scanners, are commonly found in manufacturing environments providing data for volumetric measurements. Current systems suffer from a significant performance limitation — they are significantly slower than widely used 2D line-scan systems. Profile scanners use a structured light source and an image sensor to capture information about the intersection of a moving physical object and a narrow plane of illumination. The goal of this project is to create a system for profile-scanning that is capable of operating at speeds and resolutions comparable to conventional 2D line-scan technology, typically in excess of 10K lines/second. In our first work, we demonstrated that using a Virtex 7, we could achieve 50K frames per second, and recent work has improved on our efforts [FPL13].
3D Scanning: Triangulation-based active 3D scanners, or profile scanners, are commonly found in manufacturing environments providing data for volumetric measurements. Current systems suffer from a significant performance limitation — they are significantly slower than widely used 2D line-scan systems. Profile scanners use a structured light source and an image sensor to capture information about the intersection of a moving physical object and a narrow plane of illumination. The goal of this project is to create a system for profile-scanning that is capable of operating at speeds and resolutions comparable to conventional 2D line-scan technology, typically in excess of 10K lines/second. In our first work, we demonstrated that using a Virtex 7, we could achieve 50K frames per second, and recent work has improved on our efforts [FPL13].
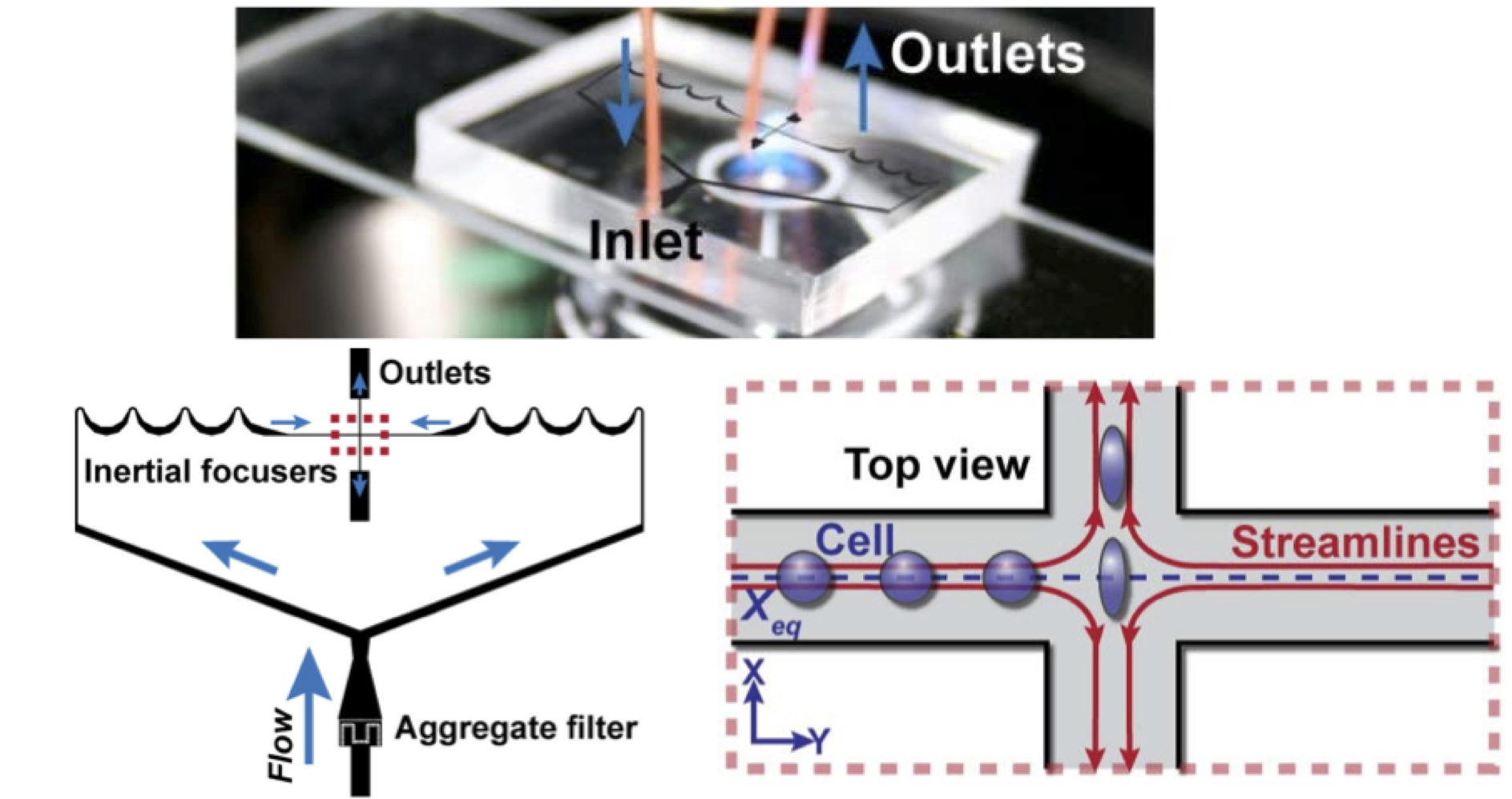
Cell Sorting: Imaging flow cytometry is a biological technique to capture and analyze morphological features of thousand of cells per second using a high speed camera. The results are use to extract cell properties to differentiate between cancerous and non-cancerous cells, mature and immatures stem cells, and other biomedical purposes. A CPU cannot provide the required compute power, thus we are building an automated cell sorting system with the goal of operating at 30,000 cell frames per second using an FPGA. To date, we have achieved more that 2,000 frames per second in throughput, which is a 38x speedup over software implementation. [JLA11, FPL13]
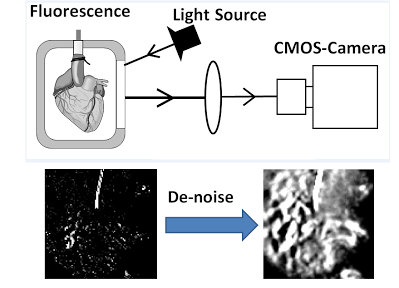 Optical Mapping is a technique for cardiac disease study and treatment to obtain accurate and comprehensive electrical activity over the entire heart. It provides a dense spatial electrophysiology. Each pixel essentially plays the role of a probe on that location of the heart. However, the high throughput nature of the computation causes significant challenges in implementing a real-time optical mapping algorithm. This is exacerbated by high frame rate video for many medical applications (order of 1000 fps). We partitioned the algorithm across CPU, FPGA, and GPU according to computational patterns and I/O bandwidths. Our FPGA-GPU-CPU heterogeneous architecture achieved the real-time throughput (1024 fps). Compared with a highly optimized multi-core CPU implementation, this heterogeneous architecture achieves a 273X speed up [EMBS12, FPT12].
Optical Mapping is a technique for cardiac disease study and treatment to obtain accurate and comprehensive electrical activity over the entire heart. It provides a dense spatial electrophysiology. Each pixel essentially plays the role of a probe on that location of the heart. However, the high throughput nature of the computation causes significant challenges in implementing a real-time optical mapping algorithm. This is exacerbated by high frame rate video for many medical applications (order of 1000 fps). We partitioned the algorithm across CPU, FPGA, and GPU according to computational patterns and I/O bandwidths. Our FPGA-GPU-CPU heterogeneous architecture achieved the real-time throughput (1024 fps). Compared with a highly optimized multi-core CPU implementation, this heterogeneous architecture achieves a 273X speed up [EMBS12, FPT12].
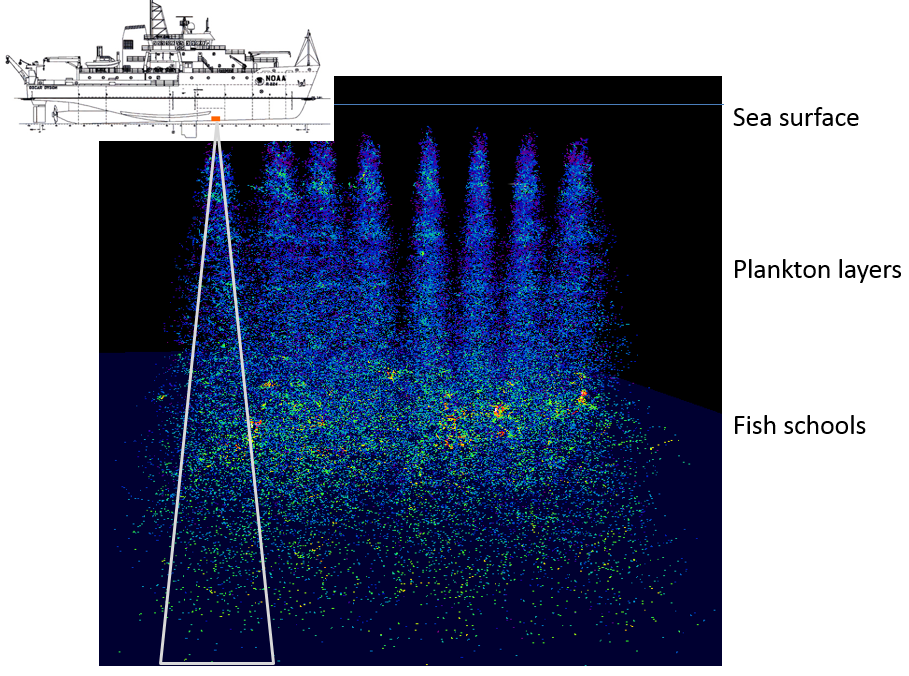 Multifrequency Biplanar Interferometric Imaging (MBI) is a contemporary acoustic-data processing technology designed to remotely image the seabed or objects in the ocean. MBI requires a computationally intense data conditioning algorithm. For example, it takes a serial central processing unit (CPU) 10 seconds to process each transmission for typical survey data from a five-beam/frequency group for split-aperture echosounders. Because many of the computations may be processed in parallel, we utilized a graphic processing unit (GPU) to accelerate the computations. The GPU implementation was 40-fold faster than the baseline serial CPU implementation [Oceans13].
Multifrequency Biplanar Interferometric Imaging (MBI) is a contemporary acoustic-data processing technology designed to remotely image the seabed or objects in the ocean. MBI requires a computationally intense data conditioning algorithm. For example, it takes a serial central processing unit (CPU) 10 seconds to process each transmission for typical survey data from a five-beam/frequency group for split-aperture echosounders. Because many of the computations may be processed in parallel, we utilized a graphic processing unit (GPU) to accelerate the computations. The GPU implementation was 40-fold faster than the baseline serial CPU implementation [Oceans13].
 Face Detection plays an important role in a wide range of embedded applications such as video surveillance, security, and robotics. To develop embedded systems for these applications on battery-operated devices, power consumption is considered one of the most important factors. This project aimed to design an Adaboost based face (object) detection algorithm on a variety of hardware acceleration platforms. The Adaboost algorithm was implemented manually using Verilog, and using a GPU [FPGA09, ASAP09, SASP09, FCCM10, ICCE-Berlin13]
Face Detection plays an important role in a wide range of embedded applications such as video surveillance, security, and robotics. To develop embedded systems for these applications on battery-operated devices, power consumption is considered one of the most important factors. This project aimed to design an Adaboost based face (object) detection algorithm on a variety of hardware acceleration platforms. The Adaboost algorithm was implemented manually using Verilog, and using a GPU [FPGA09, ASAP09, SASP09, FCCM10, ICCE-Berlin13]
 Face Recognition identifies the names or IDs of faces from an image. Our system first detects (finds locations) of a face, and then identifies them. Real-time recognition is important because many applications, e.g., surveillance and human computer interaction systems, require latency within the limits of human perception. Our system runs in real-time, has reasonable accuracy, and has the ability to be employed in an embedded system. In this project, we aim to implement the complete face recognition system on a low power and high-performance FPGA device [FCCM11].
Face Recognition identifies the names or IDs of faces from an image. Our system first detects (finds locations) of a face, and then identifies them. Real-time recognition is important because many applications, e.g., surveillance and human computer interaction systems, require latency within the limits of human perception. Our system runs in real-time, has reasonable accuracy, and has the ability to be employed in an embedded system. In this project, we aim to implement the complete face recognition system on a low power and high-performance FPGA device [FCCM11].